
HtmlScraperAnalzyer
Html Scrapping in Squirrel is available on the HtmlScraperAnalyzer. As an analyzer, the scraper will use yaml files for each one of the websites that will be scraped, containing all syntax to found elements in the page. It is necessary to declare the env variable HTML_SCRAPER_YAML_PATH, pointing to the folder where the yaml files are stored. If the variable is not present, the HtmlScraperAnalyzer will not be executed.
An example of yaml scraping file for crawling the data portal mcloud.de is described as it follows:
file_descriptor:
check:
domain: mcloud.de
ignore-request: false
search-result-page:
regex:
- results/searchAction
- results/search
resources:
"$uri":
"http://squirrel.dice_research/dataset#Link": .search-filtered .border-left a
"http://squirrel.dice_research/dataset#Page": .pagination a
download_page:
regex: results/detail
resources:
"$uri":
"http://squirrel.dice_research/dataset#File": .matadata-table aThe file must have the file_descriptor key, as well the check value, containing the domain of the portal that will be scraped. If this structure is not followed, an exception will be throw. The analyzer will check a map of loaded domains, checking all the files found by the variable HTML_SCRAPER_YAML_PATH.
For each one of the pages that will be scraped, should be included two values: regex and resources. If the file does not follow this hierarchy, an exception will be throw. These values are described as follows:
- regex: the substring of the page's context that could match the URI
- resources: a list of resources, predicates and the respective objects. For querying elements, the scraper uses the CSS selector from Jsoup. It uses a jquery-like selector syntax to select html components instead of Xpath, but it is very simply to use. For syntax reference, please look at https://jsoup.org/apidocs/org/jsoup/select/Selector.html. The query should be defined as the object. You can use some variables to define the name of your resources. $uri will use the current page's url. $label will use the last context of the url.
In the example given, the Analzyer will get every link in the query result page, and all the pagenation link as well. Observe that the regex for the search-result-page contains results/searchAction and results/search. Using the following url as seed: https://mcloud.de/web/guest/suche/-/results/searchAction, we will get all the result datasets, which will match the page descripted on the file, because the regex contains on the url. With each result link scraped, they will be sent to the Frontier and will match the download page, scraping the RDF file available on each dataset page.
You can test your JSoup queries at try.jsoup.org. Use Fetch URL to fetch the desired page and start testing. Let's take as an example the URL : https://mcloud.de/web/guest/suche/-/results/searchAction?_mcloudsearchportlet_query=&_mcloudsearchportlet_sort=latest . The URL will be a match for the regex results/searchAction.
Use your favorite browser inspector mode to analyze the html elements and css classes that contains the information that you want to scrap. Using tryjsoup, we can see the results for our query (.search-filtered .border-left a) as shows the image below:
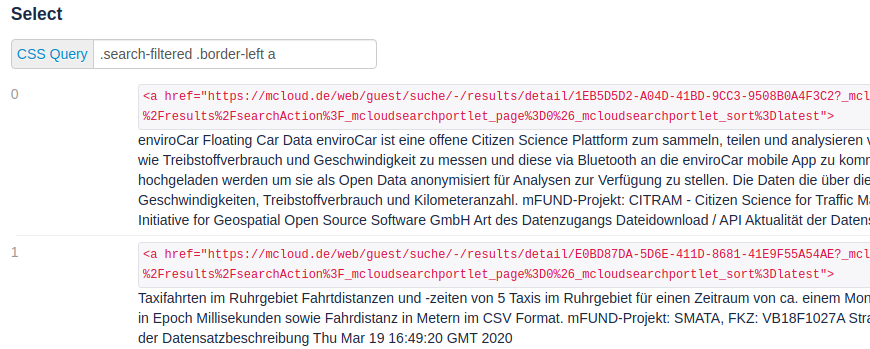
This will extract all the links from the result page. The Html Analyzer will detect automatically <a> link elements and extract the URL from it.
Also, we need to scrape the pagination links, so the crawler can visit each one of the pages:
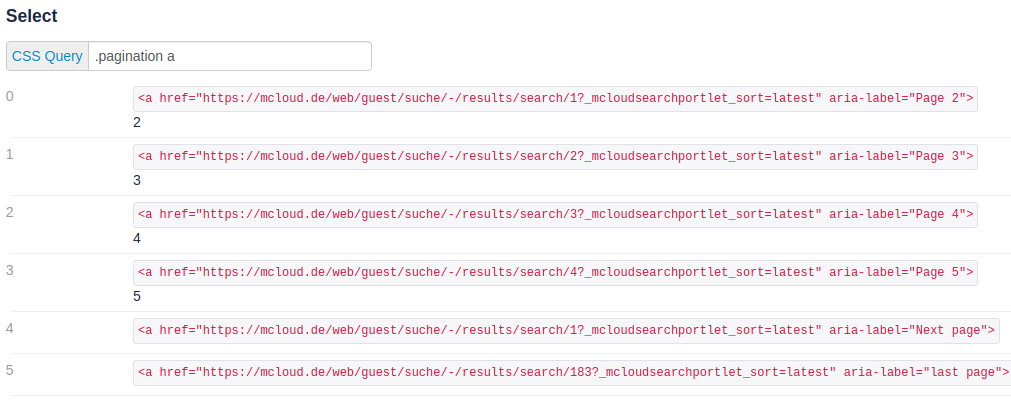
For the detail page, if the regex matches URL that contains results/detail, it will scrape the link for the RDF file, available on each dataset page.
For this scraping task, it was used both the HTMLScraperAnalyzer and the RDFAnalyzer, to extract triples from the dataset's RDF File.