
Overview
Crawling data across the web deals with large datasets, requiring a good data organization, in order to classify and to index those datasets, to make then more useful. Representing differents datasets in a unique format, makes it easier to introduce common methodologies or algorithms to extract insights or predictions from different types of complex data. The state of the art to handle this complexity of data is its representation or modelling in the form of Linked RDF Data.
RDF, as its name states, is a framework to describe resources used in the web. It is a standard developed by the World Wide Web Consortium (W3C) intended to describe metadata – data of data. This description allows for computers to understand the information contained in your human-readable document, and the fact that it is standardized provides a set of rules for collaborative systems to understand each other’s data. The way you describe data when using RDF is through simple statements that have a subject, a predicate, and an object.
SQUIRREL is crawling engine that provides tools to crawl linked data, in different serialization types.
SQUIRREL have an extensible API that allows users to create theirs own rules for extraction, analyzation of data and storage.
Squirrel Core Architecture
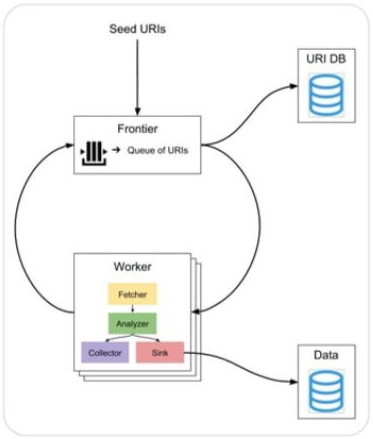
Squirrel Core is divided in two main components: frontier and worker. The execution of Squirrel requires one frontier running, while the user can set how many workers the system supports.
The frontier is initialized by a list of input seeds. It will add all the identified URI's to a queue and to a filter. Once the frontier receives a call from a worker, will give all the URI's in the queue to the worker.
The worker will only be initialized if there is a frontier available to connect to. Initially, it will request new URI's to crawl to the frontier. Then, it will fetched data available from the URI. After fetching, it will analyze the fetched file to extract triples from it and thus, store data in a sink. To read more about fetcher, analyzer and sink, read the components section. In the end, all the URI's found by the analyzer will be serialized and sent to the frontier. The frontier receives these new URI's, checks if they are present in the filter and add to the queue only the ones that not.
The frontier also register the IP number of the URI and assigns that IP to the first worker that requests it. By doing that, a worker will be responsible for crawling URI's from the same IP number.
For details about frontier and worker initialization, please visit the downloads & usage section.