
What is Squirrel?
Squirrel is a crawler of Linked Data, in order to exploit all the content of the linked web. By ingesting initial seeds, it follows all the links availables and performs a deep search to crawl everything. Squirrel has a extensible architecture allowing the user to customise the type of content that wants to crawl. Thus, it is possible to transform non linked data on RDF graphs.
How Squirrel Works ?
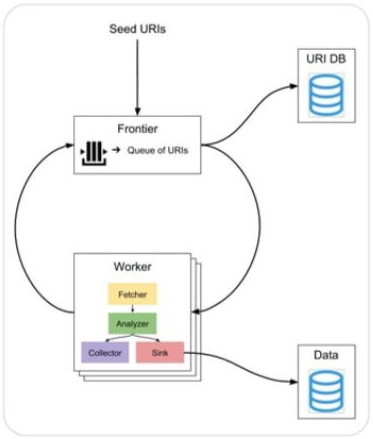
Squirrel uses data from any endpoint as input seeds. Once the URL is stored in the Queue, its data will be fetched, analyzed and found triples will be stored.
In Squirrel, the distributed architecture allows you to adjust the scalability to the needs. By using its extensive framework, it is possible to create custom components allowing to convert data not only to RDF serialization, but to any other that can describe a graph relationship.
To know more about Squirrel, please read the downloads and usage and documentation overview sections.